The Ultimate Guide to S3 in AWS: Everything You Need to Know
Part - 03 Exploring the Bucket Versioning in S3 bucket: A Guide to how to use Versioning in S3 bucket.


In this blog, we will discuss the options available after the creation of the S3 bucket.
Here we will see how to configure our S3 bucket after its creation.
In the previous blog, we saw how to create the S3 bucket and its basic configuration. Please go through the link below.
https://hashnode.com/post/clghz80xh00000akva9ga167o
Use the link above to create the S3 bucket.
Once the bucket is created successfully, then click on the bucket name you will see the window below.
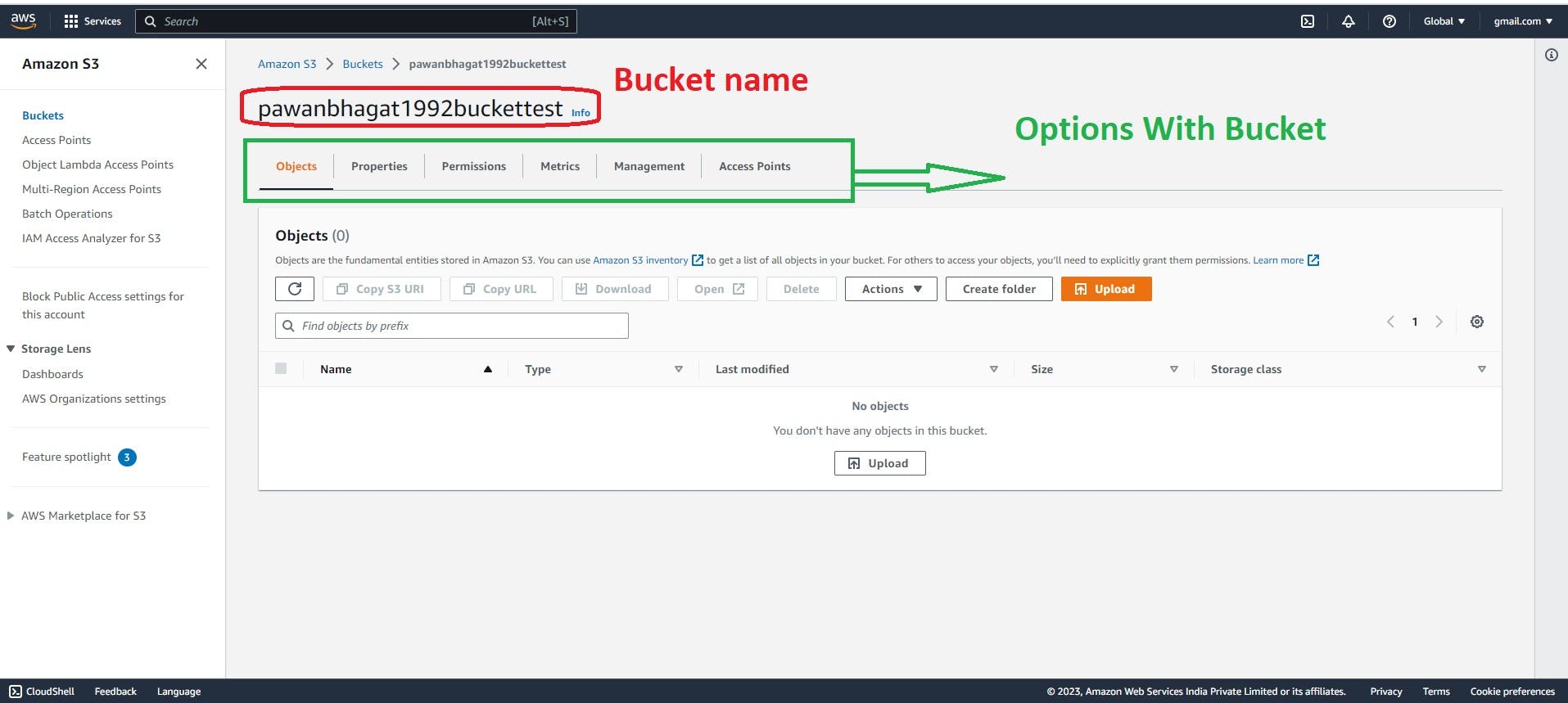
First, we will see the configuration options which are in the properties
Bucket Versioning
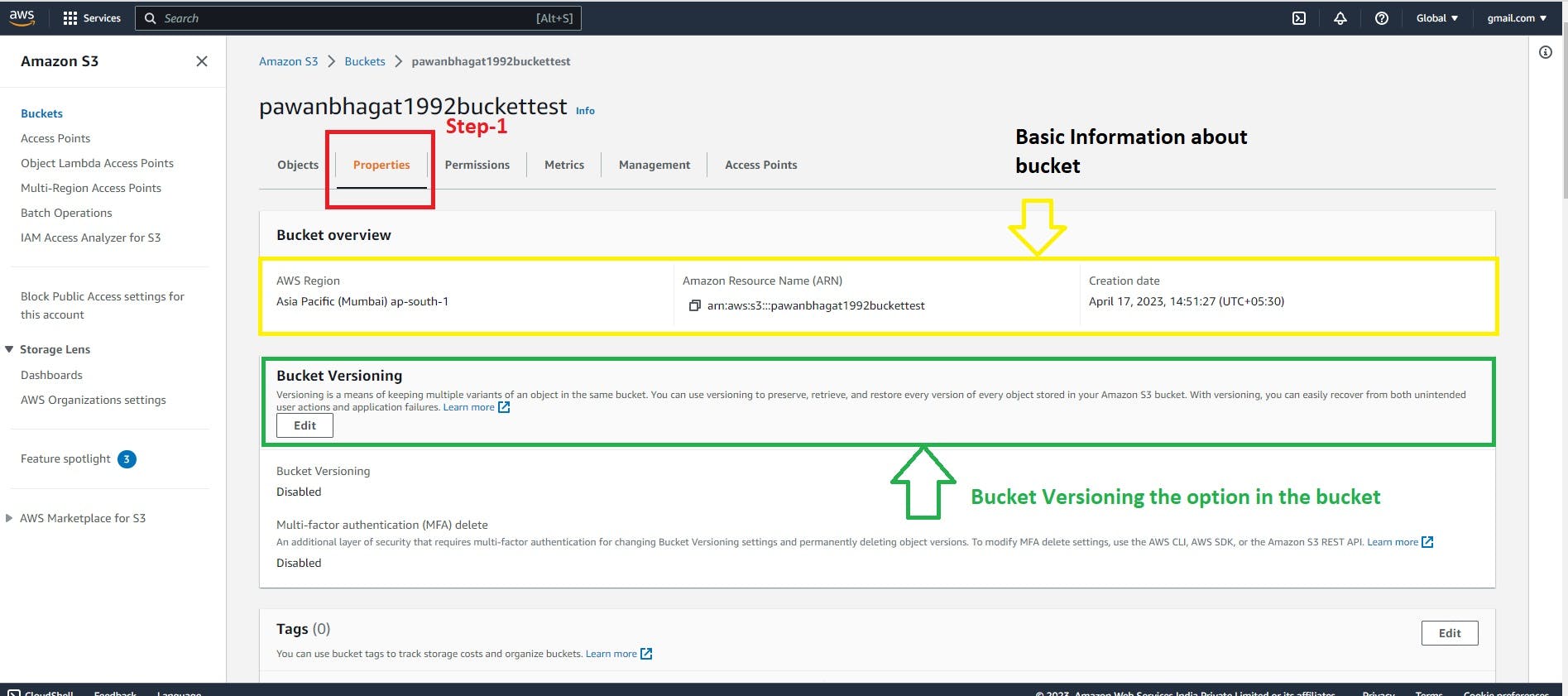
Bucket versioning is an option in Amazon S3 that allows you to keep multiple versions of an object in the same bucket. This helps you to preserve, retrieve, and restore every version of every object in your bucket. It also provides an added layer of protection against accidental deletion or overwrites.
After creating the bucket, the bucket versioning option is disabled by default.
We have enabled it manually. click on the bucket versioning option edit it and make it enable.
How do we use the Bucket versioning option?
As we know, once we enable the bucket versioning option on the S3 bucket then we can recover the accidentally deleted files and also maintain the multiple versions of files.
What are multiple versions of files?
Suppose we upload the file, which is a test1 file with one line of code, and upload it to an S3 bucket. After adding a second line to the same file, we upload the same file again to the bucket; S3 will maintain each file that has one line of code as well as those that have a second line of code. In short, S3 storage saves an individual file on each update with the same name.
Let's See how it works
Once the bucket is created click on the bucket name you will see below screen.
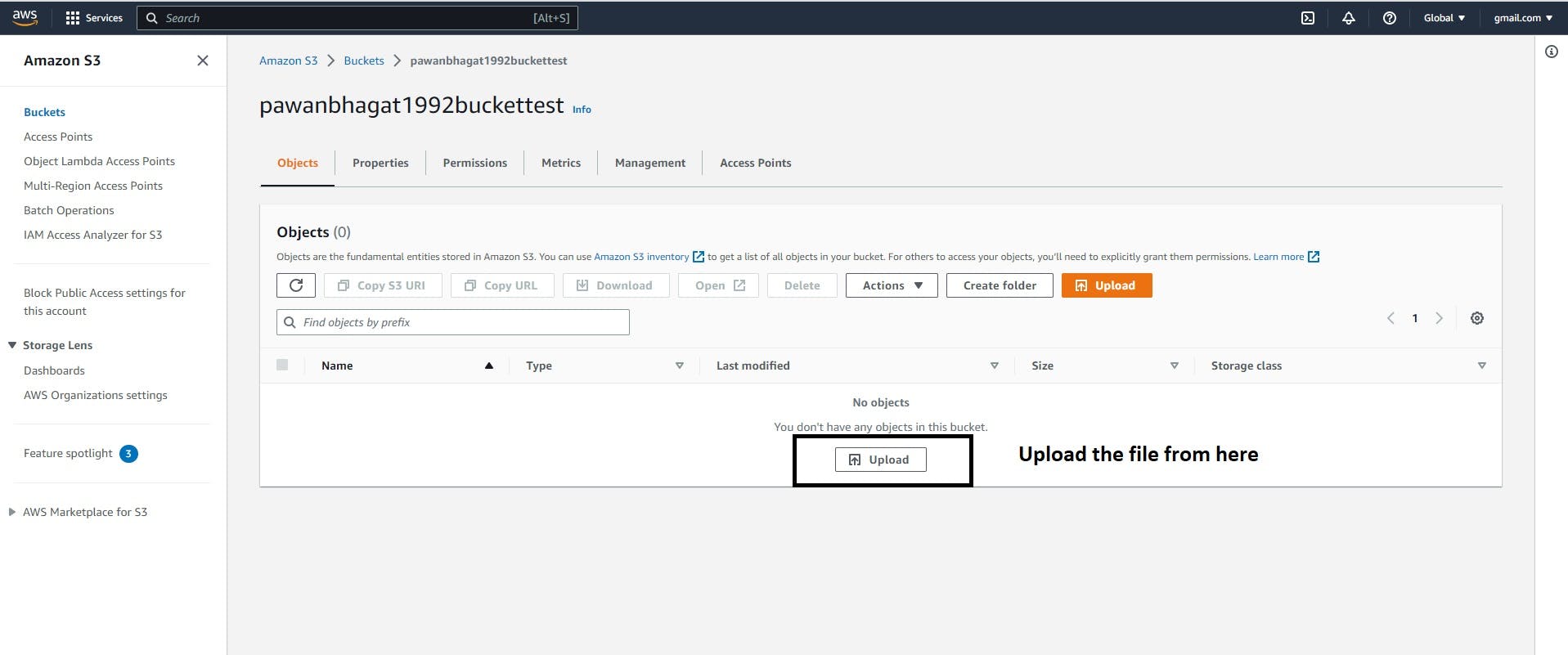
Now I am creating one dummy test file on my desktop with a single line of code
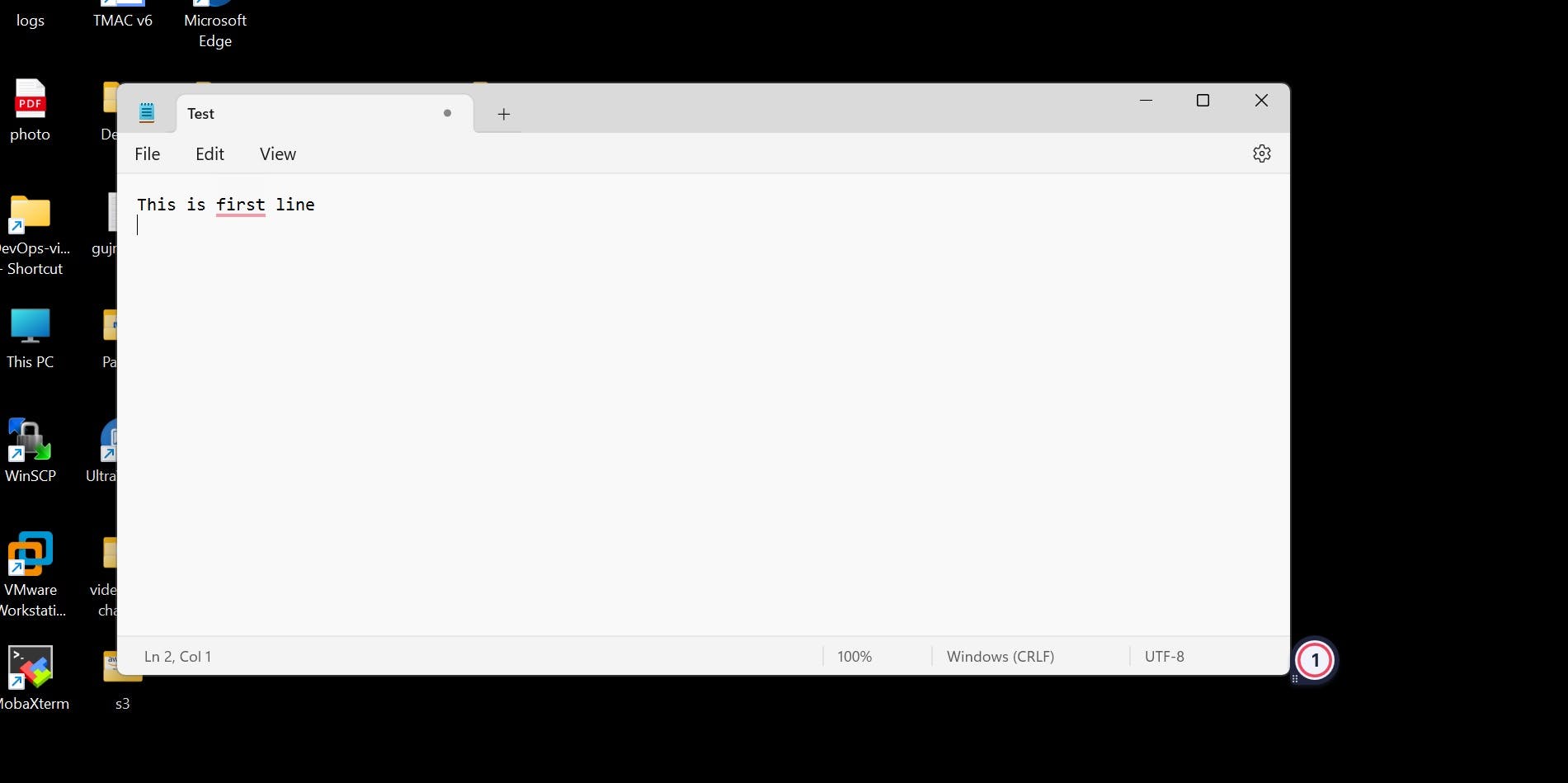
And uploaded this test file to the S3 bucket
Click on Upload
Click on Add files
Select the test file which we are created
Go to permission in the Access Control List (ACL)
make it public
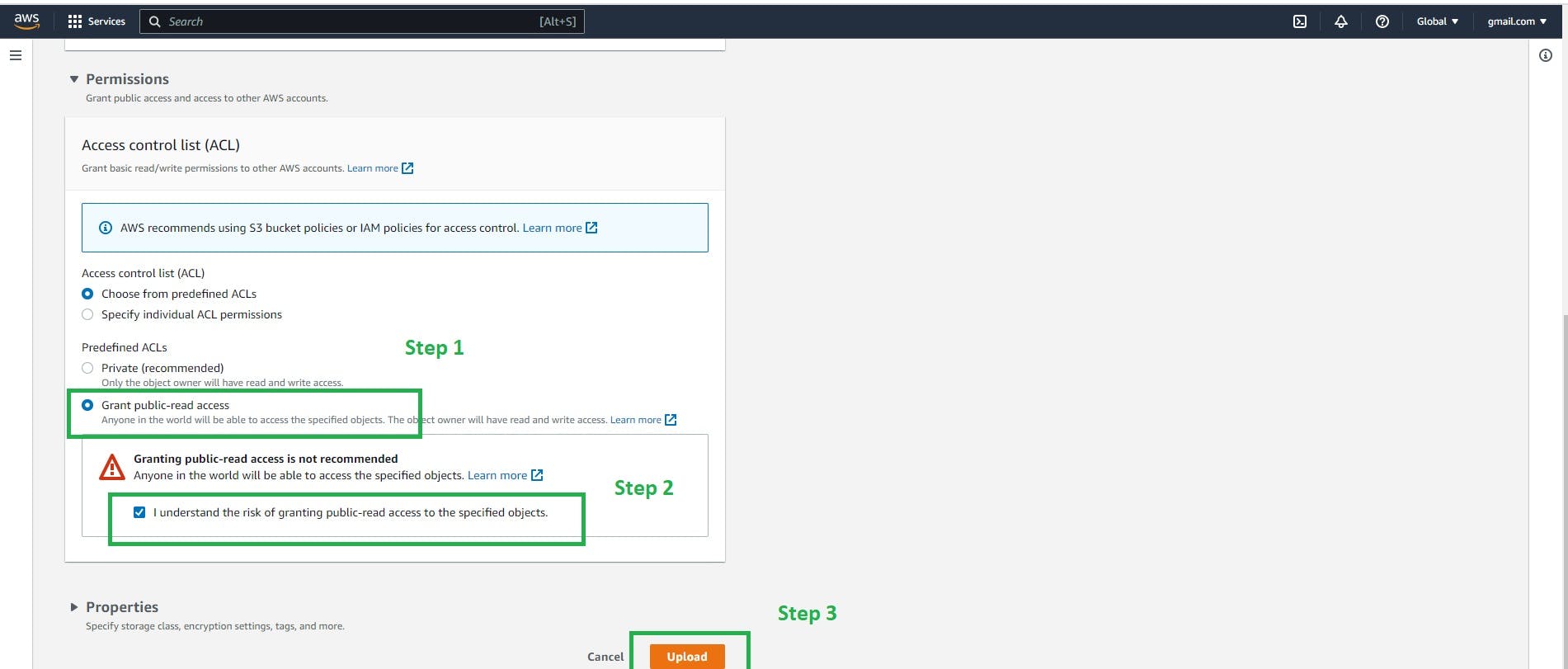
Once the file is uploaded click the close tab then you will see the below screen

Here our file is uploaded successfully.
Now we have to configure bucket versioning
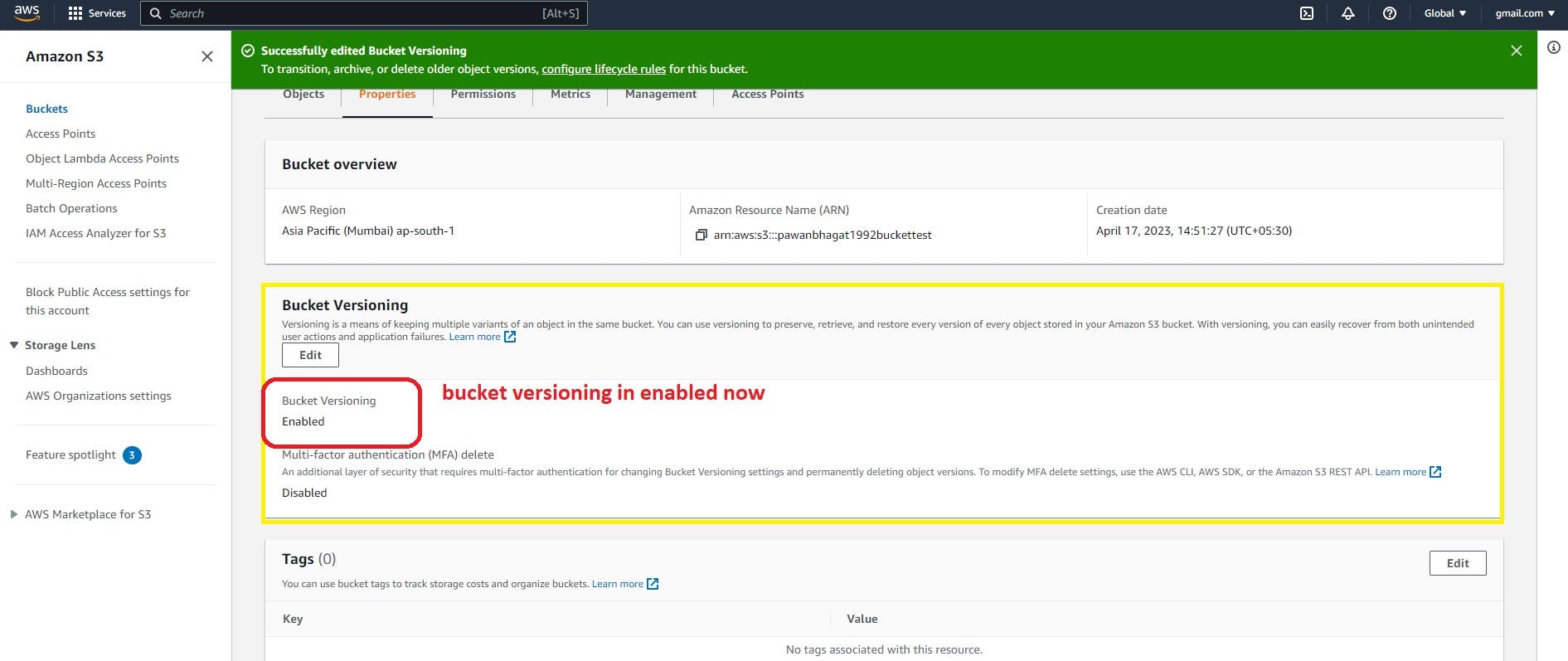
Go to properties and click on edit on bucket versioning

And enable it and click on Save changes

Once the configuration is done now, we will see how the Revision (maintaining multiple versions of a file) is done.
How do we verify that bucket versioning is enabled?
The first way you can check the configuration setting from the properties
and the second way is once you are on the object tab there is showing one option which is to show versions

This option is showing when we enabled the versioning
Till now we uploaded a single file, if we click on the show version it shows only one version of that file.
Now we can add one extra line to that test file and upload it with the same name.
Again, I am adding line no 3 and uploading it with the same name
Don't forget to make it public.
Now the output like below

This is how the S3 bucket maintains the multiple versions of files
We can download each version of a file by selecting it and clicking on the Download tab, which is on top.
How do we recover deleted files in S3 storage?
We have already one test file which is uploaded to our S3 bucket
Now I am going to delete it

Now the object is deleted successfully see in below image
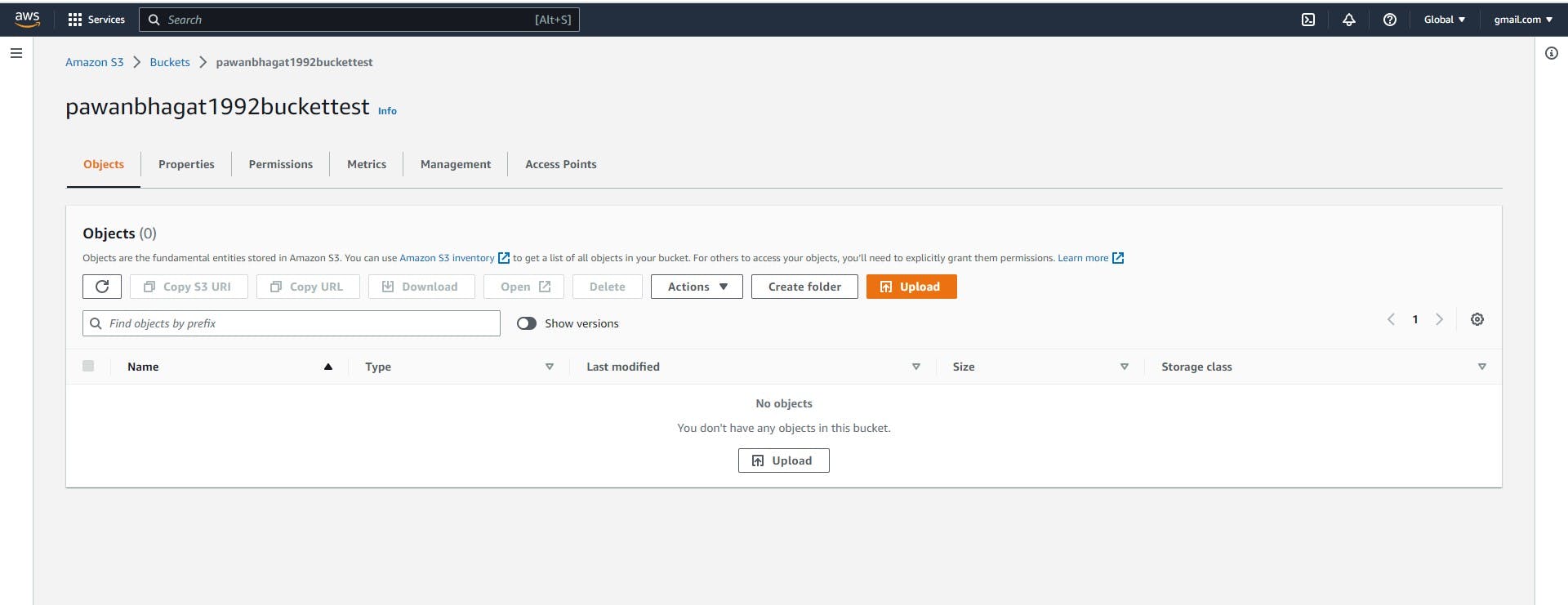
Now I have to recover the object(file) which are deleted accidentally
For that follow the below steps
Click on Show versions
then it is showing like below

There is a delete maker which is like a wall, the file which is being accidentally deleted which is kept behind the delete maker wall.
To recover the file, we have to delete the delete maker
How will it be done?
Click on delete maker file
and delete it

Once the delete maker is deleted our file is recovered with all versions successfully see in below image

This is how we can recover the file which is deleted
Here we have to know something essential about versioning in the S3 bucket
In revision, we can maintain multiple versions of a file.
If we deleted the latest version then it is possible to recover it
And if we delete the older version of the file then there is no way to recover it.
Advantages
Recover accidentally deleted files.
Maintain different file versions.
Drawbacks
Consume more disk space because it maintains different versions of files.
If the older version of the file is deleted then it is not possible to recover it.
Once the practice is completed then first Empty the bucket and after that delete the bucket.
The S3 bucket will delete only when it is empty.
Thank you for taking the time to read my blog. I hope you found it informative and engaging.
Your interest and support mean a lot to me and motivate me to keep writing.
If you have any feedback or suggestions, please don't hesitate to leave a comment or contact me directly. Once again, thank you for reading, and I hope to see you again soon.
Pawan JD Bhagat